
~その1.結論とシラバス~では判決の内容と、その結論にいたる大枠の論理を抽出して説明しました。
趣旨を繰り返しますと、
・GoogleによるUIの複製は、あるコンピューティング環境において培われた技能(Java SEのスキル)が他の環境でも役立つようにするために行われた。
・コピーした行は宣言コード(declaring code)であり、約11,500行だったが、これは全体の0.4%だった。(これは「全体」の捉え方次第で変わってしまう気がしますが。。。)
・GoogleによるコピーはAndroidプラットフォームのために行われたものだが、AndroidプラットフォームはJava SEの市場に影響を与えず、むしろ利益を与えることすらある。
ということです。
ここで、判決文では図を用いて技術的な事項、特に上記のJava SEや宣言コード(declaring code)に関する内容が解説されています。
今回はその内容を見ていきたいと思います。
理解の助けのため「ソフトウェアプラットフォーム」とは何かを説明する。簡単に言えば、ソフトウェアプラットフォームは、プログラマーがコンピュータープログラムを構築するために必要となる可能性のあるすべてのソフトウェアツールの集まりである。たとえば、Androidプラットフォームには、「オペレーティングシステム」、「コアライブラリ」、「仮想マシン」などのツールを含む。
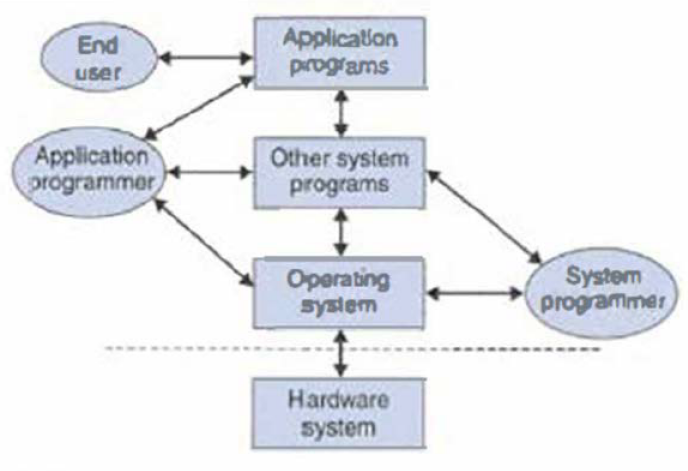
この図は、標準的なコンピュータシステムの一般的な機能を示してる。点線は、コンピュータのハードウェアとそのソフトウェアの区分を示す。 (本件における特定のテクノロジーを反映することを意図したものではない。)
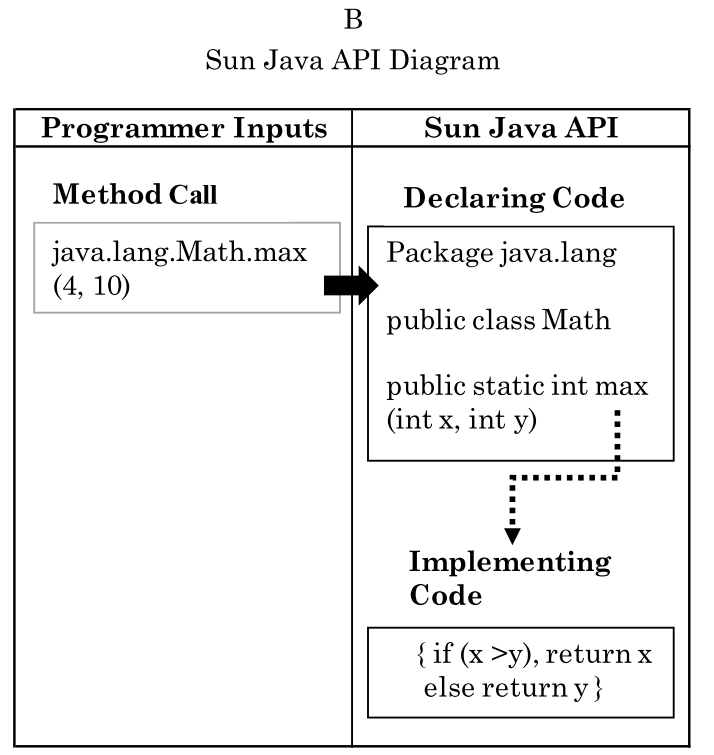
この画像は、地裁の例による本件に関するSun JavaAPIテクノロジーの3つの部分間の接続を示している。プログラマーはメソッドコールを入力して、API内からタスクを呼び出す(実線の矢印)。メソッドコールの正確な記号は、特定のクラス(Public class Math)内にある単一のタスクに対応している。そのクラスは特定のパッケージ(Package java.lang)内にある。この構成及びメソッド、クラス、パッケージの名前を提供する全ての行は宣言コード(declaring code)である。各メソッドについて、宣言コードは実装コード(Implementing Code)の特定の行({if(x>y),return X else return y})に関連付けられている(点線の矢印)。プログラマーのアプリケーションでコンピューターに実際に指示するのは、この実装コードであり、GoogleがAndroid API用に作成したものである。
この内容を理解しておくと、結論とシラバスにおいて説明されていた
・GoogleによるUIの複製は、あるコンピューティング環境において培われた技能(Java SEのスキル)が他の環境でも役立つようにするために行われた。
・コピーした行は宣言コード(declaring code)であり、約11,500行だったが、これは全体の0.4%だった。
という点がある程度実感をもって理解できるようになってくるかと思います。
エンジニアにとってのJava SEのスキルとは具体的に何を意味するか、その一つがこの「宣言コード(declaring code)」の知識量でしょう。判決本文でも、「Java言語に精通している人は、無数のタスクを呼び出すことができる無数のメソッドコールをすでに知っています。」と説明されています。Java SE環境における「宣言コード(declaring code)」の知識がAndroid環境でも役立つとなれば、Java SEのスキルを有するエンジニアをAndroid環境に呼び込むことができる。そのためにJava SEの「宣言コード(declaring code)」をそのままAndroid環境に移植する必要があった。
ただし、実際にコンピューターを作動させるプログラムである実装コード(Implementing Code)までコピーしてしまうと、それは完全にプログラム著作物の著作権侵害という可能性が濃くなってしまうので、その部分はAndroid側で独自に用意した。
※尚、図中では「実装コード(Implementing Code)」の部分は({if(x>y),return X else return y})という簡潔な形で表現されていますが、判決本文では「単一のタスクで数百行の長さになる」と説明されています。
逆に言えば、GoogleはAndroidのプログラミング環境ために独自に各種の「実装コード(Implementing Code)」を作成したが、Java SE環境と共通する機能については、Java SE環境における「宣言コード(declaring code)」でその機能を呼び出せるようにした。
ということがよくわかります。
なるほど、この内容を理解すると、判決に対する理解度が全く違ってきます。
実際に「プログラム」として動作する部分、つまり上記の「実装コード(Implementing Code)」の部分はGoogleが独自に作成したという部分が非常に心象として強く感じられ、これは「フェアユース」だと認識されるのもわかる反面、「宣言コード(declaring code)」の部分だってプログラムのコードであることに変わりはないわけで、全体の0.4%であったとしても約11,500行という量をコピーされた側が著作権侵害だ!と憤る気持ちもわかります。
そういった意見の対立が、フェアユースの4つの判断基準、即ち、(1)使用の目的と性質、(2)著作物の性質、(3)著作物全体に関連して使用される部分の量と実質性、そして、(4)著作物の潜在的な市場または価値に対する使用の影響、という基準で判断された訴訟ということです。
判決文では、上記の4つの判断基準についてそれぞれ論じられていますので、次からはそれを見ていきたいと思います。




“米国最高裁判決、グーグルvオラクル Java訴訟 ~その2.技術的事項の説明~” への7件のフィードバック